
近期,阿里云機(jī)器學(xué)習(xí)平臺PAI發(fā)表的多篇論文在ICCV 2023上入選。ICCV是國際計(jì)算機(jī)視覺大會是由電氣和電子工程師協(xié)會每兩年舉辦一次的研究大會。與CVPR和ECCV一起,它被認(rèn)為是計(jì)算機(jī)視覺領(lǐng)域的頂級會議之一。ICCV 2023將于10月2日至10月6日法國巴黎舉辦。ICCV匯聚了來自世界各地的學(xué)者、工程師和研究人員,分享最新的計(jì)算機(jī)視覺研究成果和技術(shù)進(jìn)展。會議涵蓋了計(jì)算機(jī)視覺領(lǐng)域的各個方向,包括圖像處理、模式識別、機(jī)器學(xué)習(xí)、人工智能等等。ICCV的論文發(fā)表和演講都備受關(guān)注,是計(jì)算機(jī)視覺領(lǐng)域交流和合作的重要平臺。
阿里云PAI總共有3篇文章入選ICCV 2023,其中阿里云與華南理工大學(xué)聯(lián)合培養(yǎng)項(xiàng)目產(chǎn)出了基礎(chǔ)模型SMT和圖像復(fù)原模型的指紋保護(hù)技術(shù)兩篇文章,阿里云與IDEA-CVR張磊團(tuán)隊(duì)合作產(chǎn)出了目標(biāo)檢測Stable DINO一篇文章。此次3篇文章入選ICCV 2023,意味著阿里云PAI在國際計(jì)算機(jī)視覺領(lǐng)域進(jìn)一步提升了影響力。
論文簡述
當(dāng)尺度感知調(diào)制遇上Transformer
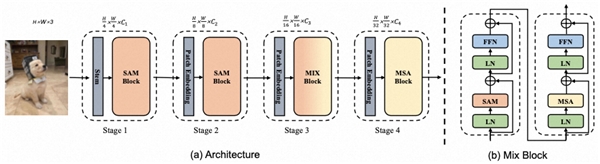
近年來,基于Transformer和CNN的視覺基礎(chǔ)模型取得巨大成功。有許多研究進(jìn)一步地將Transformer結(jié)構(gòu)與CNN架構(gòu)結(jié)合,設(shè)計(jì)出了更為高效的hybrid CNN-Transformer Network,但它們的精度仍然不盡如意。本文介紹了一種新的基礎(chǔ)模型SMT(Scale-Aware Modulation Transformer),它以更低的參數(shù)量(params)和計(jì)算量(flops)取得了大幅性能的提升。
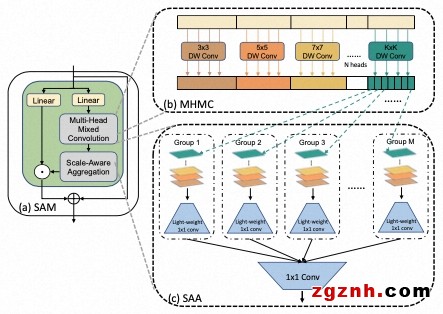
不同于其他CNN-Transformer結(jié)合的方案,SMT基于卷積計(jì)算設(shè)計(jì)了一個新穎的輕量尺度感知調(diào)制單元Scale-Aware Modulation(SAM),它能夠捕捉多尺度特征的同時擴(kuò)展感受野,進(jìn)一步增強(qiáng)卷積調(diào)制能力。此外,SMT提出了一種進(jìn)化混合網(wǎng)絡(luò)Evolutionary Hybrid Network(EHN),它能夠有效地模擬網(wǎng)絡(luò)從淺層變深時捕捉依賴關(guān)系從局部到全局的轉(zhuǎn)變,從而實(shí)現(xiàn)更優(yōu)異的性能。在ImagNet、COCO以及ADE20k等任務(wù)上都驗(yàn)證了該模型的有效性。值得一提的是,SMT在ImageNet-22k上預(yù)訓(xùn)練后以僅僅80.5M的參數(shù)量在ImageNet-1k上達(dá)到了88.1%的精度。
總的來說,在視覺基礎(chǔ)模型backbone的探索路程中,我們有著對未來的展望:
以視覺Transformer為例,除了在自監(jiān)督學(xué)習(xí)等預(yù)訓(xùn)練中依舊用著ViT這種plain Vision Transformer,大部分視覺基礎(chǔ)模型都以Swin和PvT這種Hierarchical架構(gòu)為基礎(chǔ)設(shè)計(jì)范式。而這種范式需要解決的問題就是如何在淺層stage中設(shè)計(jì)更高效的注意力機(jī)制計(jì)算來解決自注意力的二次復(fù)雜性帶來的計(jì)算負(fù)擔(dān)。是否有更優(yōu)秀的計(jì)算模塊能夠代替SAM或者是MSA是我們后續(xù)需要繼續(xù)探索的路。2023年,更多的視覺Transformer模型和CNN基礎(chǔ)大模型被提出,它們在各大榜單上你追我趕,可以發(fā)現(xiàn)CV領(lǐng)域中CNN依舊有著一席之地。如果Transformer不能夠在CV領(lǐng)域完全替代cnn神經(jīng)網(wǎng)絡(luò),那么將兩者的優(yōu)勢結(jié)合起來是否是更好的選擇?因此,我們希望SMT可以作為Hybrid CNN-Transformer方向新的baseline,推動該領(lǐng)域的進(jìn)步和發(fā)展。
穩(wěn)定匹配策略提升Detection Transformer上限
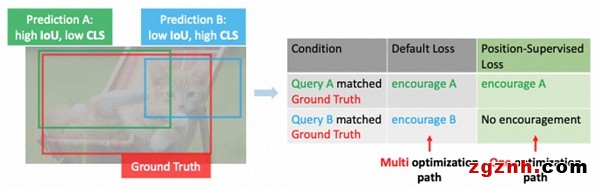
本文指出在DETR中存在的不穩(wěn)定的匹配問題是由多重優(yōu)化路徑導(dǎo)致的,而這個問題在DETR的one-to-one matching中會變得更加明顯。我們表明僅需要在分類損失中引入了位置度量就可以很好的優(yōu)化DETR中存在的不穩(wěn)定匹配問題。并且基于這一原則,我們通過引入了位置度量信息提出了兩個簡單有效并且可以適用于所有DETR系列模型的position-supervised loss和position-modulated matching cost設(shè)計(jì)。此外,我們提出了密集memory融合來增強(qiáng)編碼器和backbone的特征。
我們在一系列DETR模型上對我們的方法有效性進(jìn)行了驗(yàn)證,其中我們的Stable-DINO以ResNet-50作為backbone的條件下在1x和2x標(biāo)準(zhǔn)settings下分別達(dá)到了50.4AP和51.5AP。并且我們的方法具有足夠強(qiáng)大的scalability,使用Swin-Large和Focal-Huge backbone的條件下Stable-DINO在COCO test-dev上分別達(dá)到了63.8AP和64.8AP的準(zhǔn)確率。
雖然我們的方法表現(xiàn)出了很好的性能,但我們只在類似 DETR 的圖像對象檢測和分割上驗(yàn)證它。諸如 3D 對象檢測之類的更多探索將作為我們未來的工作。此外,我們只關(guān)注損失和匹配中的分類部分,而保留定位部分。對定位部分的分析也留作我們未來的工作。
針對圖像復(fù)原模型的指紋保護(hù)技術(shù)
深度學(xué)習(xí)已經(jīng)成為解決計(jì)算機(jī)視覺問題的一個突出工具,在開源社區(qū)中共享預(yù)先訓(xùn)練的DNN模型已經(jīng)成為一種常見做法,許多公司和機(jī)構(gòu)也提供付費(fèi)的商用預(yù)訓(xùn)練模型服務(wù)。這為不法使用者抄襲/竊取模型創(chuàng)造了強(qiáng)烈動機(jī),例如使用惡意軟件感染或內(nèi)部泄漏等方法來規(guī)避昂貴的訓(xùn)練過程。因此,社區(qū)和公司都有強(qiáng)烈需求來保護(hù)其DNN模型的知識產(chǎn)權(quán)。保護(hù)DNN模型知識產(chǎn)權(quán)的一種流行方案是模型數(shù)字水印,它會侵入地嵌入被稱之為水印的特定信息到源模型中,并檢查該水印在可疑模型中的存在。然而,侵入式嵌入會修改模型權(quán)重,進(jìn)而可能會影響模型的效用,在實(shí)踐中變得不那么理想。
最近,一種非侵入式的方法稱為模型指紋技術(shù)受到了關(guān)注。與模型水印不同,指紋技術(shù)不會修改模型任何參數(shù),其從模型中提取出稱為指紋的唯一特征來識別其所有權(quán)。通過比較源模型的指紋與可疑模型的指紋來驗(yàn)證模型的所有權(quán)。現(xiàn)存的深度模型指紋方案大部分僅聚焦在圖像分類問題上,如使用決策邊界點(diǎn)作為指紋,針對深度圖像復(fù)原網(wǎng)絡(luò)的指紋方案尚未發(fā)表。圖像復(fù)原模型的應(yīng)用已然十分廣泛,如圖像去噪、超分辨率、去模糊等。因此,為探究圖像復(fù)原任務(wù)中的非侵入式模型保護(hù)方法,我們首次提出了一種針對深度圖像復(fù)原模型的指紋方案。
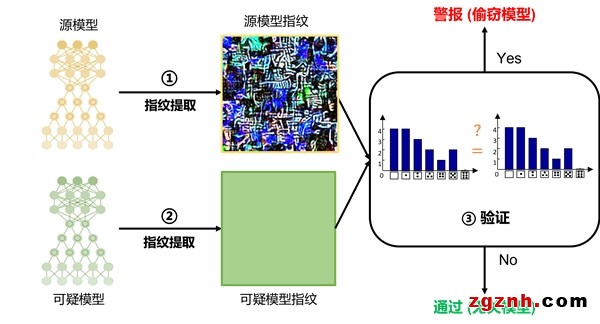
如下圖所示,我們方法整體步驟如下:
Step1. 對源模型提取指紋;Step2. 對可疑模型提取指紋,可疑模型可能是違規(guī)獲取的被攻擊模型,也可能是無關(guān)的清白模型,指紋驗(yàn)證的目的是能夠區(qū)分兩者;Step3. 驗(yàn)證兩組指紋的相似性,通過對兩組指紋分別做特征提取,并根據(jù)在特征與統(tǒng)計(jì)層面上計(jì)算的偷竊概率來進(jìn)行判斷。
指紋提取的思路主要是基于模型反演的思想,固定模型優(yōu)化圖像,找出一張恰好使得模型復(fù)原難度均衡的臨界圖像,圖示如下:
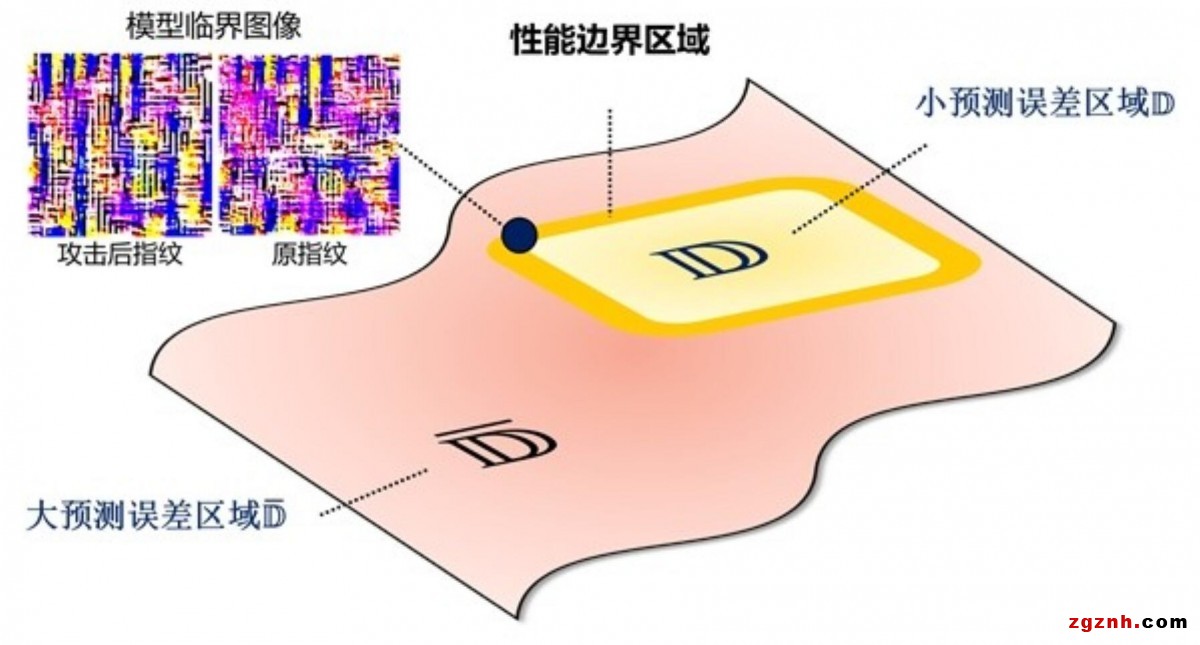


方案優(yōu)缺點(diǎn)
對比模型水印方案,我們指紋方案最大的優(yōu)點(diǎn)在于完全不會改變深度圖像復(fù)原網(wǎng)絡(luò)的參數(shù),進(jìn)而不會對模型性能產(chǎn)生任何影響,同時經(jīng)實(shí)驗(yàn)驗(yàn)證能夠抵御常見的模型攻擊手段。但目前我們的指紋驗(yàn)證方案需要獲取模型的梯度信息,也就是說對比之前的黑盒水印驗(yàn)證流程,驗(yàn)證方需要具備更高的權(quán)限。因此,優(yōu)化驗(yàn)證階段也將成為我們未來的方向。
算法開源
為了更好地服務(wù)開源社區(qū),上述兩個算法的源代碼已經(jīng)開源。另外,我們正在開發(fā)PAI上輕松訓(xùn)練推理部署上述算法的框架,大概會在10月推出,敬請期待。
Github地址:
https://github.com/AFeng-x/SMT
modelscope地址:
https://modelscope.cn/models/PAI/SMT/summary
阿里云機(jī)器學(xué)習(xí)平臺 PAI 多篇論文入選 ICCV 2023
● 論文標(biāo)題:
Scale-Aware Modulation Meet Transformer
● 論文作者:
林煒豐、吳梓恒、陳佳禹、黃俊、金連文
● 論文PDF鏈接:
https://arxiv.org/pdf/2307.08579.pdf
● 論文標(biāo)題:
Detection Transformer with Stable Matching
● 論文作者:
劉世隆、任天和、陳佳禹、曾兆陽、張浩、李峰、李弘洋、黃俊、蘇航、朱軍、張磊
● 論文PDF鏈接:
https://arxiv.org/pdf/2304.04742.pdf
● 論文標(biāo)題:
Fingerprinting Deep Image Restoration Models
● 論文作者:
全宇暉、滕寰、許若濤、黃俊、紀(jì)輝
● 論文PDF鏈接:
https://csyhquan.github.io/manuscript/23-iccv-Fingerprinting%20D
 粵公網(wǎng)安備 44030702001206號
粵公網(wǎng)安備 44030702001206號